
(a)Problem review:
 is a random variable and
is a random variable and  is a random variable, where
is a random variable, where  and
and 
 and
and  can be thought of as the failure rate for each respective component.
can be thought of as the failure rate for each respective component.  is the lifetime of
component
is the lifetime of
component  . Hence
. Hence  means to ask for the probability of the first component to have a lifetime of
means to ask for the probability of the first component to have a lifetime of
 given that the failure rate of this kind of components is
given that the failure rate of this kind of components is 
solution:
Now we know that

Looking at the following diagram to help determine the region to integrate:
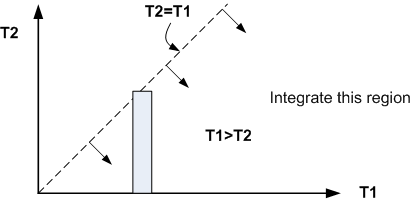
Hence

But since  then the joint density is the product of the marginal densities.
then the joint density is the product of the marginal densities.
Hence

Therefore

We take  since we expect the lifetime to go to zero eventually. Also this is a requirement for the
integrals to not diverge.
since we expect the lifetime to go to zero eventually. Also this is a requirement for the
integrals to not diverge.
Hence the above becomes

Hence

(b)

Hence

Hence

(c)Need to find  which is the same as
which is the same as  , hence this is the same as part(a) but
replace
, hence this is the same as part(a) but
replace  by
by  as show in the following diagram
as show in the following diagram
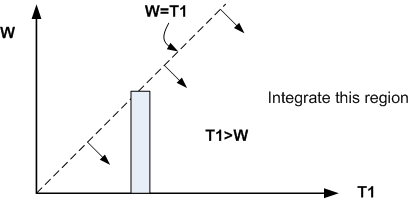
Hence

Hence

Then


Problem review: Poisson probability density is a discrete probability function (We normally call
it the probability mass function  ). This means the random variable is a discrete random
variable.
). This means the random variable is a discrete random
variable.
The random variable  in this case is the number of success in
in this case is the number of success in  trials where the probability of success
in each one trial is
trials where the probability of success
in each one trial is  and the trials are independent from each others. The difference between
Poisson and Binomial is that in Poisson we are looking at the problem as
and the trials are independent from each others. The difference between
Poisson and Binomial is that in Poisson we are looking at the problem as  becomes very large and
becomes very large and
 becomes very small in such a way that the product
becomes very small in such a way that the product  goes to a fixed value which is called
goes to a fixed value which is called
 , the Poisson parameter. And then we write
, the Poisson parameter. And then we write  where
where  The
following diagram illustrates this problem, showing the three r.v. we need to analyze and the time
line.
The
following diagram illustrates this problem, showing the three r.v. we need to analyze and the time
line.
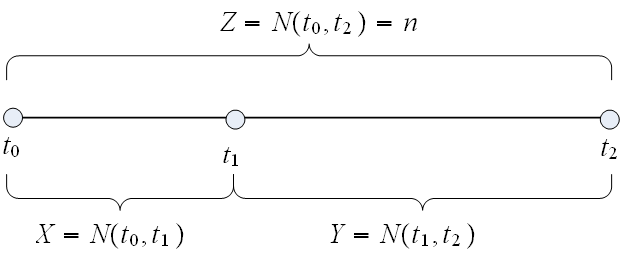
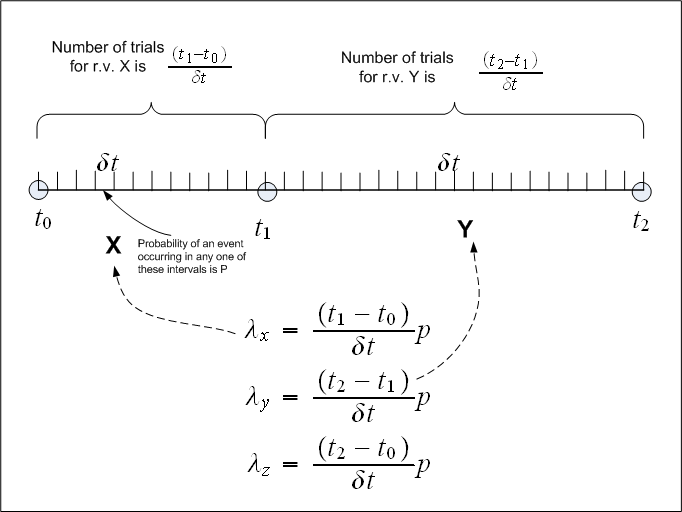
But what is "trials" in this problem? If we divide the time line itself into very small time intervals  then
the number of time intervals is the number of trials, and we assume that at most one event will occur in this
time interval (since it is too small). The probability
then
the number of time intervals is the number of trials, and we assume that at most one event will occur in this
time interval (since it is too small). The probability  of event occurring in this
of event occurring in this  is the same in the interval
is the same in the interval
![[t0,t1]](q342x.svg) and in the interval
and in the interval ![[t1,t2]](q343x.svg) . Now let us find
. Now let us find  for
for  and
and  and
and  based on this. Since
based on this. Since  where
where  is the number of trials, then for
is the number of trials, then for  we have
we have  where we divided the time interval
by the time width
where we divided the time interval
by the time width  to obtain the number of time slots for
to obtain the number of time slots for  . We do the same for
. We do the same for  and obtain that
and obtain that

Similarly,  , hence
, hence 
Let us refer to the random variable  as
as  and the r.v.
and the r.v.  as
as  and the r.v.
and the r.v.  as
as 
The problem is then asking to find  and to identify
and to identify 
To help in the solution, we first draw a diagram to make it more clear.
We take  to the same for the
to the same for the  random variables
random variables  .
.

But  is the same as
is the same as  hence
hence

Now r.v. 
 , since the number of events in
, since the number of events in ![[t0, t1]](q375x.svg) is independent from the number of events that
could occur in
is independent from the number of events that
could occur in ![[t1,t2]](q376x.svg) .
.
Given this, we can now write the joint probability of  as the product of the marginal probabilities.
Hence the numerator in the above can be rewritten and we obtain
as the product of the marginal probabilities.
Hence the numerator in the above can be rewritten and we obtain
 | (1) |
Now since each of the above is a Poisson process, then

Hence (1) becomes
 | (2) |
Hence

But we found that  , hence the exponential term above vanish and we get
, hence the exponential term above vanish and we get

Let  , then
, then  hence the last line above can be written
as
hence the last line above can be written
as

But this is a Binomial with parameters  , hence
, hence


part (a)
Let  the probability of getting heads, be the specific value that the random number
the probability of getting heads, be the specific value that the random number  can
take.
can
take.
Let  be the probability density of
be the probability density of  , which we are told to be
, which we are told to be ![U [0,1]](q393x.svg) , and let
, and let  be the
probability mass function of the random variable
be the
probability mass function of the random variable  where
where  is the number of times until a head first comes
up.
is the number of times until a head first comes
up.  is then a geometric random variable with parameter
is then a geometric random variable with parameter  , hence
, hence

The posterior density of  given N is then
given N is then

But

and  since
since ![Θ ˜U [0,1]](q3104x.svg)
Hence
 | (1) |
But  is a random continuous variable from
is a random continuous variable from ![[0,1]](q3107x.svg) , so how to evaluate the above? I can evaluate the
above for different values of
, so how to evaluate the above? I can evaluate the
above for different values of  on the real line from
on the real line from ![[0,1]](q3109x.svg) , and the more values I take between
, and the more values I take between  the more
accurate
the more
accurate  will become.
will become.
Part(b)
First let me evaluate eq (1) for 
For 
![|--|
h (Θ = 𝜃|X = 1) = ∫-𝜃----= [-𝜃]--= 2 𝜃|
1𝜃 d𝜃 𝜃2 1 ----
0 2 0](q3114x.svg)
For 

For 

We can use integration by parts for the denominator, where  , when we do this we
obtain
, when we do this we
obtain

Now we plot the above 3 cases on the same plot:
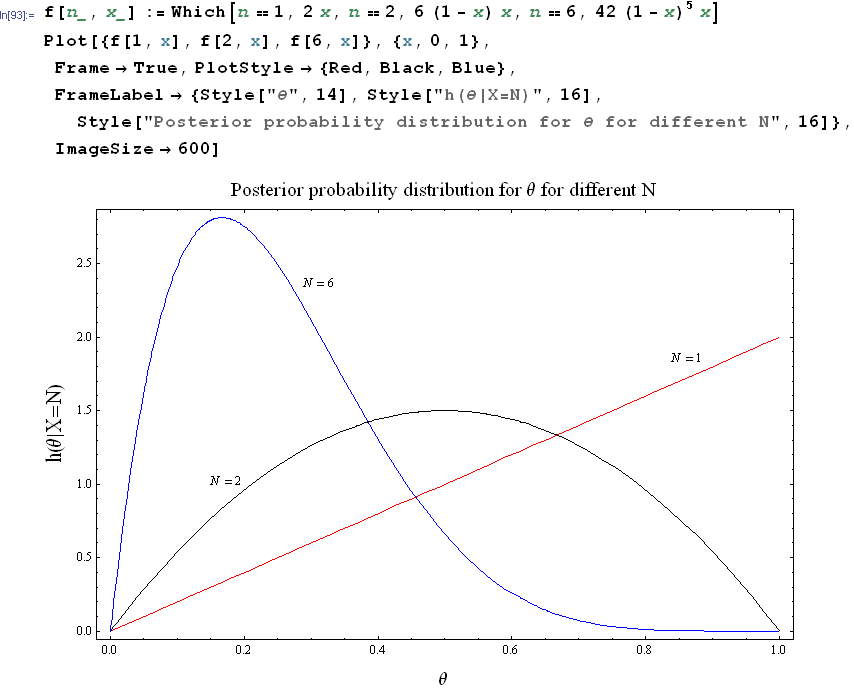
What the above plot is saying is the following:
If it takes 'longer' to see a head comes up ( ), then the coin is taken as biased towards a tail, and the
probability of getting a head becomes smaller, this is why we see that the most likely probability in this
case to be around
), then the coin is taken as biased towards a tail, and the
probability of getting a head becomes smaller, this is why we see that the most likely probability in this
case to be around  (looking at the N=6 curve). We say that based on the observation of
(looking at the N=6 curve). We say that based on the observation of
 , then the coin has a higher probability of having its probability of getting a head to be about
, then the coin has a higher probability of having its probability of getting a head to be about
 than any other value. (The area around
than any other value. (The area around  is larger than any other area for the same
is larger than any other area for the same
 )
)
Now, when  , i.e. we flipped the coin 2 times, and got a head on the second time, then we see from
the
, i.e. we flipped the coin 2 times, and got a head on the second time, then we see from
the  curve that the coin has a most likelihood of having a probability of getting a head to be
0.5
curve that the coin has a most likelihood of having a probability of getting a head to be
0.5
This is what we would expect, since in an unbiased coin, the probability of getting a head is  , and hence
with a fair coin, we expect to see a head half of the times it is flipped, and since we flipped 2 times, and saw
a head the second time, this posterior probability has its most likely value to be around .5 as
well.
, and hence
with a fair coin, we expect to see a head half of the times it is flipped, and since we flipped 2 times, and saw
a head the second time, this posterior probability has its most likely value to be around .5 as
well.
When  , this says that we got a head in the first time we flipped the coin. We see that the posterior
probability of getting a head now has it maximum around 1. This means the posterior probability is saying this
coin is biased towards a head.
, this says that we got a head in the first time we flipped the coin. We see that the posterior
probability of getting a head now has it maximum around 1. This means the posterior probability is saying this
coin is biased towards a head.
The above is a method to estimate the probability distribution of the probability itself of getting a head based on the observed events and based on the prior known probability of getting a head. Hence the events observed allow us to estimate the probability of getting a head. Hence the posterior probability is conditioned on each event as in this problem.